یکی از مسائل مهم در ساخت مدل یادگیری ماشین و هوش مصنوعی توجه ویزه به موضوع کمبرازش و بیشبرازش است تا بتوانیم در نهایت یک مدل عمومیتر و قابل قبول بسازیم. این موضوع با پیچیدگی مدل یادگیری ماشین در ارتباط است و محاسبات بایاس و واریانس نیز ابزار مناسبی برای تشخیص هستند.
[برگرد بالا]
در حوزهی یادگیری ماشین دو مفهوم کمبرازش (آندِرفیت یا Underfitting) و بیشبرازش (اُورفیت یا Overfitting) نقش اساسی در ارزیابی کیفیت مدل دارند. اگر یادگیری مدل و ارزیابی آن را معادل یادگیری یک درس و آزمون برای یک واحد درسی در نظر بگیریم، بیشبرازش به معنی آن است که مدل جزوهی درسی را حفظ کرده است و اگر آزمون از همان جزوه بیاید نمرهی خوبی میگیرد. اما اگر سوالی خارج از جزوه داده شود به مشکل میخورد. در نقطهی مقابل بیشبرازش، مدلی که در وضعیت کمبرازش قرار داشته باشد، حتی اگر از خود جزوه نیز آزمون بگیریم مدل نمرهی خوبی نمیگیرد و در کل عملکرد ضعیفی دارد. در وضعیت کمبرازش الگوی مناسبی حتی برای دادههای یادگیری پیدا نشده است و در حالت بیشبرازش این الگو بسیار وابسته به خود دادههای آموزشی هستند. بنابراین هر دو حالت نقطهی مقابل یک مدل خوب با قابلیت عمومیسازی آن هستند و باید از وقوع آنها جلوگیری کنیم.
یک مدل خوب یادگیری ماشین مدلی است که اگر بر اساس یادگیری با یک مجموعه دادهی آموزشی مشخص عملکرد مناسبی دارد، با هر زیرمجموعهی به اندازهی کافی مناسب آن مجموعه نیز همان عملکرد را داشته باشد. به همین ترتیب اگر در دادههای آموزشی تغییرات بسیار جزئی به عنوان نویز ایجاد کنیم، پارامترهای مدل جدید نیز نباید تغییر چشمگیری داشته باشد و در واقع عملکرد مدل اصلی نباید چندان تغییر کند. پس اگر با تغییر جزئی در دادهها یا تغییر زیرمجموعه، پارامترهای مدل نیز تغییر چشمگیر داشته باشند، مدل به خود دادهها حساس است و در وضعیت بیشبرازش قرار دارد.
[برگرد بالا]
پیچیدگی مدل در یادگیری ماشین به میزان توانایی آن در شناسایی و یادگیری الگوهای موجود در دادهها اشاره دارد. بهعنوان نمونه، یافتن الگوها در تصاویر معمولا به مدلهای پیچیدهتری نیاز دارد، تا برآورد قیمت یک خانه بر اساس ویژگیهای آن ساختمان. روش کنترل پیچیدگی در مدلهای مختلف متفاوت است. در رگرسیون خطی با افزایش تعداد ویژگیها یا افزودن جملههای چندجملهای، تعداد پارامترها افزایش یافته و در نتیجه مدل پیچیدهتر میشود. در مدلهایی مانند درخت تصمیم نیز معیارهایی نظیر عمق درخت یا تعداد تقسیمبندیها شاخص مناسبی برای سنجش پیچیدگی به شمار میآیند. البته باید توجه داشت که حتی دو مدل با تعداد پارامتر مشابه میتوانند ظرفیتهای بسیار متفاوتی در یادگیری الگوهای پیچیده داشته باشند.
[برگرد بالا]
منظور از بایاس در دنیای یادگیری ماشین، متوسط خطای برآورد مدل نسبت به مقدار واقعی به ازای یادگیری با مجموعه دادههای مختلف با توزیع یکسان است و واریانس این برآوردها نیز میزان پراکندگی را مشخص میکند. در چهار تصویر زیر هر شلیک معادل برآورد یک برآورد برای یک نقطهی ثابت با مدلهای مختلفی است که با دادههای با توزیع یکسان یادگیری داشتهاند. هر چه این نقاط به مرکز نزدیک باشند متوسط فاصلهی آنها از مرکز کمتر است و بایاس کمی داریم. به همین ترتیب هرچه پراکندگی نقاط نسبت به هم کمتر باشد، واریانس پایین است.
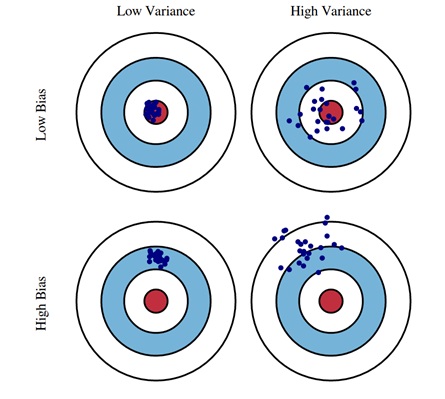
همانطور که پیشتر اشاره شد، هر زیرمجمومهی تصادفی به اندازهی کافی بزرگ با خود مجموعه داده توزیع یکسانی دارند. بنابراین در محاسبهی بایاس و واریانس میتوانیم مدلها را با زیرمجموعههای تصادفی مجموعهی اصلی آموزش دهیم.
[برگرد بالا]
شاید برای شما هم پیش آمده باشد که در برخی رستورانها یا مراکز عرضهی غذا، قیمتها بهطور غیرعادی پایینتر از عرف جامعه باشد. جدا از نیت خیرخواهانهی صاحب آنجا، معمولا اولین فکری که به ذهنمان خطور میکند این جمله است: «معلوم نیست از چی درست شده!» این جمله در واقع به این نکته اشاره دارد که اگرچه آن غذا ارزان است، اما ممکن است در ادامه هزینههای پنهانی، مانند عوارض سلامتی، به همراه داشته باشد که حتی گرانتر از یک غذای سالم گران باشد. به بیان دیگر: «هیچ ناهاری رایگان نیست».
تئوری ناهار رایگان (No Free Lunch یا NFL) یکی از اصول طنزآلود اما مهم در ریاضیات و یادگیری ماشین است. این تئوری یادآوری میکند که هیچ الگوریتمی وجود ندارد که برای تمام مسائل بهترین باشد؛ هر بهبودی در یک زمینه، هزینهای در زمینهای دیگر به همراه دارد. به همین دلیل، تغییر در تنظیمات یک مدل اگرچه میتواند کیفیت خروجی یا هزینه محاسبات را بهبود دهد، اما ممکن است در جای دیگری پیامدهای منفی ایجاد کند. یکی از نمونههای این وضعیت، دستکاری میزان پیچیدگی مدل است.
در ویدئوی زیر ارتباط پیچیدگی مدل یادگیری ماشین با وقوع کمبراش یا بیشبرازش و ارتباط آنها با بایاس و واریانس با چند مثال بررسی شده است.
بایاس-واریانس، کمبرازش-بیشبرازش و ارتباطشان با پیچیدگی مدل یادگیری ماشین
کدهای بحث شده در پیوند زیر منتشر شدهاند.
Bias-Variance.ipynb
جمعبندی و نکات تکمیلی
در ادامه جمعبندی نوشتههای فوق به همراه برخی نکات تکمیلی و مفید آمده است.
[برگرد بالا]کمبرازش زمانی رخ میدهد که مدل نتواند الگوهای اصلی موجود در دادهها را به درستی یاد بگیرد. در این حالت حتی روی دادههای آموزشی عملکرد ضعیفی دارد و دقت آن پایین است.
[برگرد بالا]بیشبرازش (Overfitting) چیست و چرا خطرناک است؟
[برگرد بالا]روشهایی مانند استفاده از دادههای بیشتر، بهکارگیری تکنیکهای منظمسازی (Regularization)، کاهش پیچیدگی مدل، استفاده از Dropout در شبکههای عصبی و بهکارگیری Cross-validation میتواند کمککننده باشد.
[برگرد بالا]مدلهایی با بایاس بالا معمولا دچار کمبرازش هستند و مدلهایی با واریانس بالا به بیشبرازش تمایل دارند. هدف اصلی، یافتن تعادلی بین بایاس و واریانس برای دستیابی به عملکرد بهینه است.
[برگرد بالا]افزایش پیچیدگی مدل میتواند باعث شود الگوهای پیچیدهتر را یاد بگیرد، اما در صورت افراط، منجر به بیشبرازش میشود. مدلهای سادهتر در مقابل ممکن است کمبرازش داشته باشند.
[برگرد بالا]با تنظیم تدریجی پارامترهای مدل، استفاده از اعتبارسنجی متقابل (Cross-validation) و بررسی عملکرد مدل روی دادههای آموزش و آزمون، میتوان این تعادل را بهدست آورد.
[برگرد بالا]این تئوری میگوید هیچ الگوریتمی برای همهی مسائل بهترین نیست. هر بهبودی در عملکرد مدل در یک نوع داده، ممکن است در نوع دیگری از داده باعث افت عملکرد شود.